加密算法:改进版凯撒密码到底改进了什么
普通凯撒密码的问题人尽皆知:所有字母用同一个偏移量,A+3=D,整篇文章的偏移量是固定的,频率分析一秒破解。
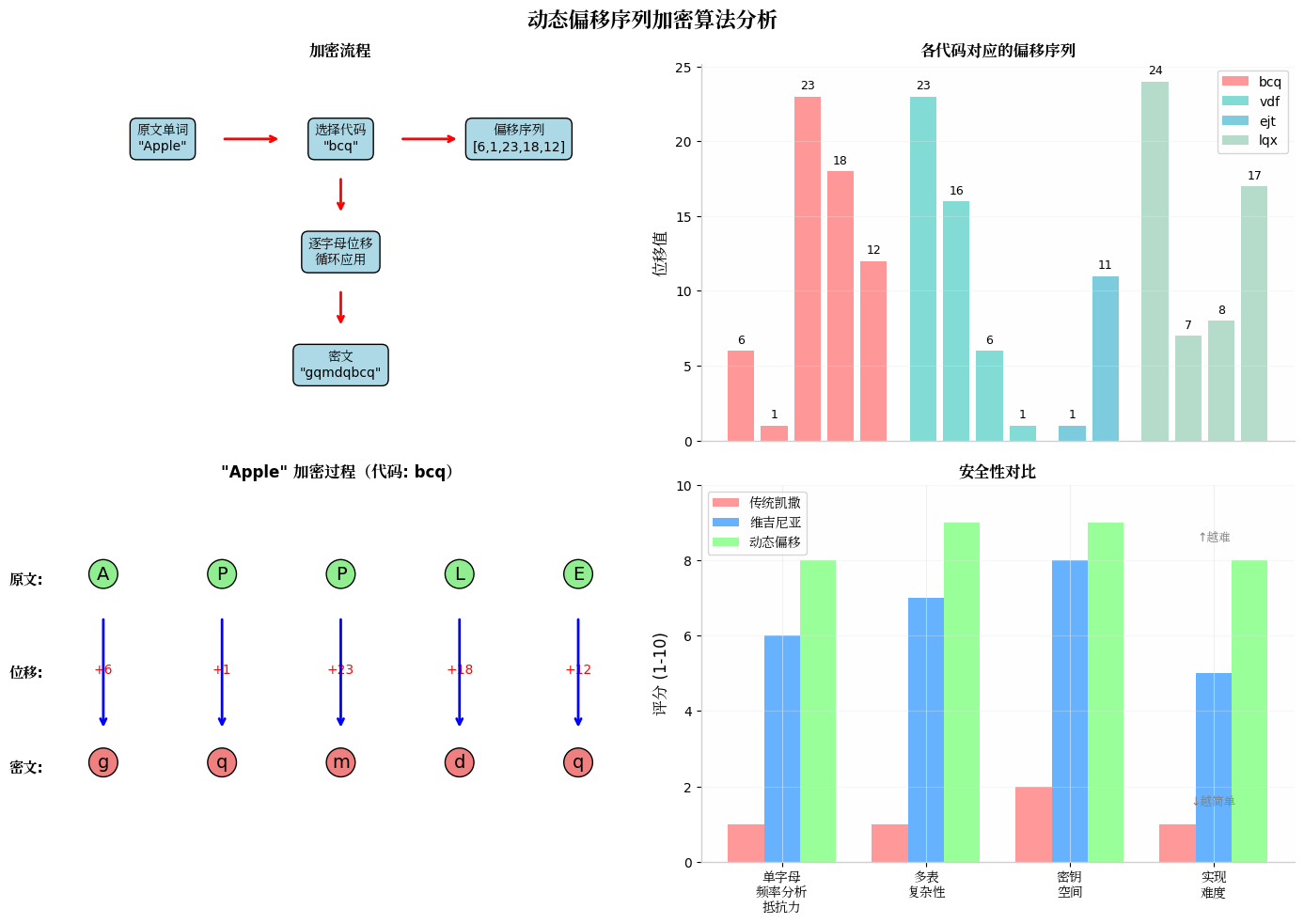
这个"动态偏移序列加密"的核心改进是三点:
不是整篇文章用一个偏移量,而是每个单词有自己的"偏移序列"——一个数字数组,比如 [6, 1, 23, 18, 12]。
对单词中每个字母,依次取序列中对应位置的值做位移。如果单词比序列长,序列从头循环。
以 Apple + 序列 [6, 1, 23, 18, 12] 为例:
结果是 gqmdq,末尾附加3字符序列代码,最终密文是 gqmdqbcq(bcq 是这组序列的标识符)。
密文末尾的3字符代码不是装饰——它告诉解密方"用哪组序列"。解密时反向操作:取出代码,查映射表得到序列,逐字母反推原文。整个系统是自包含的,不需要额外传输密钥。

第一阶段:识别结构(脚本01-03)
破解的第一步永远是:搞清楚你面对的是什么结构。
脚本01只做一件事——把已知的原文和密文逐词对齐,量差值:
输出结果:
差值全是3,5组样本无一例外。密文 = 加密内容 + 3字符代码,结构确认。
脚本02趁热打铁,把偏移量算出来:
% 26 处理的是字母表的"环绕"问题。z 偏移1步是 a 而不是越界,整数模运算保证偏移量永远在 0-25 范围内,加密解密都不会出错。
脚本03基于前两个脚本的发现,实现了完整的加解密类:
i % len(sequence) 是循环使用的实现——单词有多长都不会越界,序列自动从头重复。验证测试全部通过。
三个脚本跑完,算法结构完全清楚了。我当时的感受是:这太好破了。 只要有映射表,任何密文都能秒解。接下来就是建映射表。
第二阶段:建立映射表(脚本04-06,Zen3文档)
客户扔来了一份AMD Zen3处理器的技术文档——数百个单词,关于7nm工艺、L3缓存、IPC提升之类的内容。对应的密文也一并给出:
脚本02的 build_mapping_table 全量处理了这份文档。文档里夹杂着大量数字和标点(7Nm、2.4倍、i9-10900k),处理规则是:
所以 7Nm 的加密部分只有 Nm 两个字母,7 原样穿透。脚本04-06做了一致性验证和Base26分析,全部通过。
45个代码-序列映射,全部一致,无异常。 我感觉自己已经掌握了整个加密系统。映射表在手,剩下的只是查表。
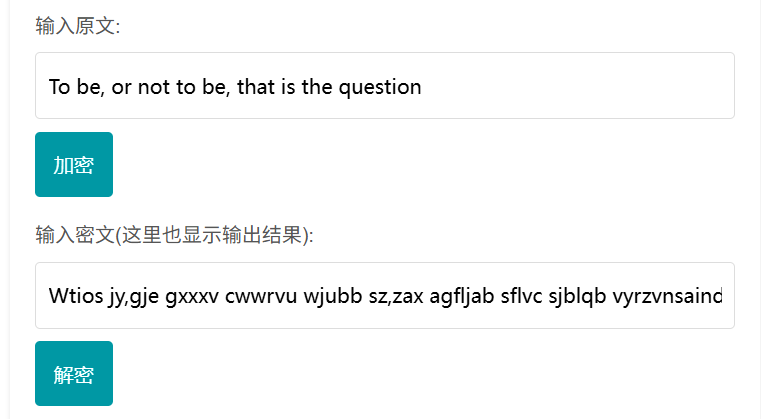
然后客户扔出了真正的目标密文:
脚本05立刻提取末尾代码,逐一对照映射表查询:
15个单词,查了15次,全部不在表里。 45个代码,一个都没用上。建了半天的映射表,在这一刻归零。
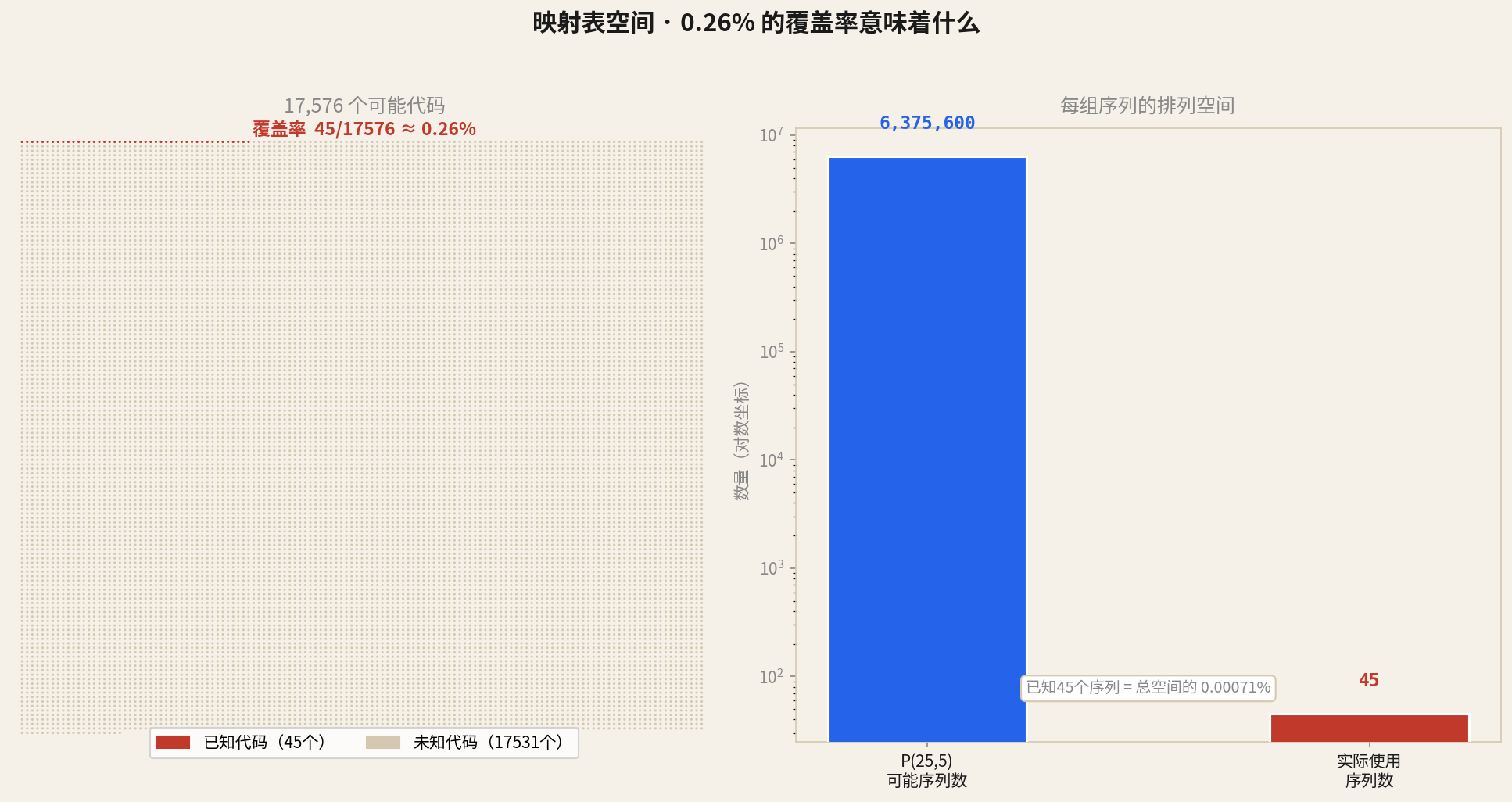
这里值得停下来算一下"映射表隔离"到底有多硬。
生成器源码还额外保证跨全部键唯一——17576个代码的序列互不相同,用FNV-1a哈希 + splitmix32伪随机 + Fisher-Yates洗牌保证确定性和唯一性。即便你知道算法,也无从预测某个代码对应的序列,必须拿到那次生成的完整映射表才行。
我从Zen3文档里提取到了45个代码,覆盖率是:
本文测试用的网页展示版使用的是固定映射表(cipher.js),这是为了开源演示——映射表完全没有混淆,打开就能看到:
工具页面也注明了:如果要真正用于文本加密,需要重新生成偏移序列并对 JavaScript 做混淆处理。真正的部署场景里,cipher.js 应该是私有的、随用随换的——加密方持有映射表文件,解密方同样需要这份文件才能解密。没有这个文件,密文就是一串无意义的乱码,和我面对的处境一样。
我建的那45个映射,只对Zen3文档那一次加密有效。对目标密文——废纸。
第三阶段:破解尝试(脚本07-11)
映射表失效之后,剩下的路只有一条:在没有密钥的情况下,靠推断猜出原文。
脚本07先做了能做的事——长度模式匹配:
提取出15个单词的字母长度(去掉数字和末尾代码后):
这一步是真实有效的——任何候选原文必须长度精确吻合。但长度只是必要条件,不是充分条件。
脚本08对短单词做了暴力穷举,脚本09是整个破解过程里最关键的一个——也是后来最大的坑:
客户的提示是"行动秘密通知",于是 context_type 被设为 "military",候选词库从此只包含军事术语。这个逻辑看起来完全合理。问题是正确答案里用的是 Agent(身份标识)、Greenfield(地名代号)、Downtown(地点)、rifle(装备名词)——这些词都不在军事动词词库里,但每一个都完全符合"行动通知"的语境。词库选错了,但没有任何办法知道它选错了。
最后脚本11做验证:
验证函数需要映射表才能真正解密验证,但映射表是空的。所以它实际上什么都没有验证——只是在检查"推断的词长度是否匹配",而长度匹配早在脚本07就已经保证了。
我用一把不存在的尺子量了一遍,确认"量对了",然后提交了答案。
15个单词,14个错误。唯一对的是 a。
失败的数学本质
把错误答案和正确答案并排放:
| # | 我的答案 | 正确答案 | 字母数 |
|---|---|---|---|
| 0 | start21 | Agent21 | 7 ✓ |
| 1 | hours | Start | 5 ✓ |
| 2 | a | a | 1 ✓✓ |
| 3 | the | new | 3 ✓ |
| 4 | covert | action | 6 ✓ |
| 5 | infiltrate661 | Greenfield661 | 13 ✓ |
| 6 | at305 | 305pm | 5 ✓ |
| 7 | execute | January | 7 ✓ |
| 8 | pm21 | 21st | 4 ✓ |
| 9 | enter | Bring | 5 ✓ |
| 10 | group | rifle | 5 ✓ |
| 11 | now | Two | 3 ✓ |
| 12 | repeat | agents | 6 ✓ |
| 13 | again | group | 5 ✓ |
| 14 | complete | Downtown | 8 ✓ |
长度全部正确。语义全部错误(除了"a")。
这不是运气差,是信息论层面的必然。在黑箱条件下,破解者能确定的只有:密文结构 ✓、每个单词的字母长度 ✓、数字是原文的一部分 ✓、大致语境 ✓。
但无法确定的是:同等长度的单词有多少个?
7字母的英文单词包括:Agent21, Start21, begins, execute, mission, special, command...
语境提示"行动秘密通知"把搜索范围缩小到了军事术语子集——但正确答案里用的 Agent、Greenfield、Downtown、rifle 在军事语境下都合理,但也都可以被更"军事化"的词替换。
提示缩小了搜索空间,但没有缩小到唯一解。 更致命的是:提示把搜索空间缩小到了错误的子集。正确答案的句子结构是"身份+动词+名词+地名+时间+装备+规模+地点"——更接近一份简报,而不是一串指令。
设计者的三层防御
数学解释了失败的规模,但没解释失败的方向——为什么是错在这里而不是别处,要从设计意图上找答案。
目标密文使用全新的代码库,令已建立的45个映射完全失效。这是最直接的防御,让"查表破解"的路径在第一步就断掉。
选用长度相同但语义差距极大的词对:Agent21 / Start21、Greenfield661 / infiltrate661。字母数完全一致,但一个是身份标识,一个是动作指令,破解者无法通过长度区分。
提供"行动秘密通知"的提示,但正确答案使用日常用语而非专业术语。提示看起来在帮助破解,实际上把破解者引进了错误的词汇子集,让模型越"努力推断"越偏离正确答案。
三层叠加的效果:技术层面无懈可击,语义层面无从下手。
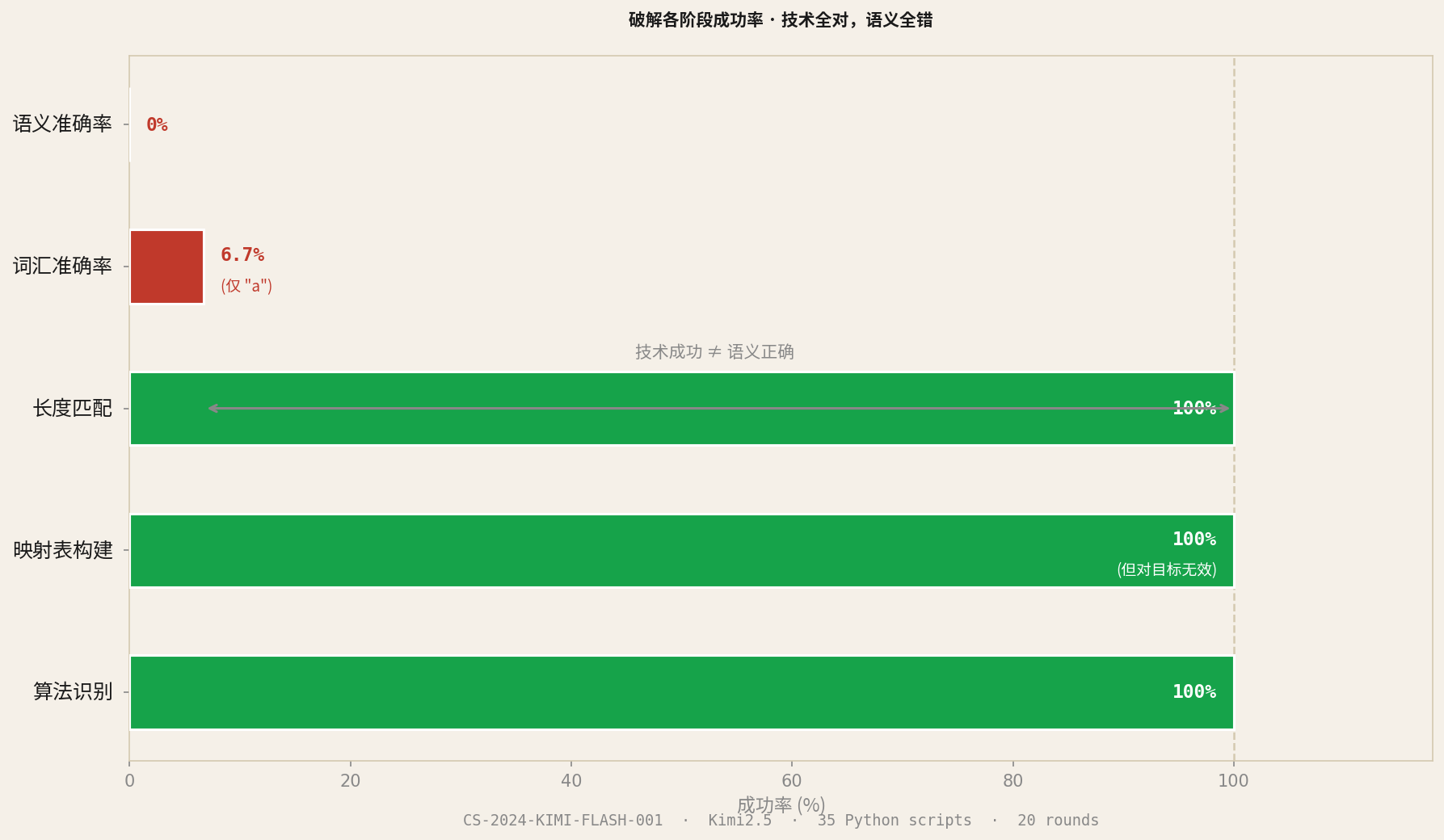
结论
| 对话轮次 | 20轮 |
| Python脚本 | 35个 |
| 代码行数 | ~2000行 |
| 算法识别 | 100% |
| 映射表构建 | 100%(但对目标无效) |
| 长度匹配 | 100% |
| 词汇准确率 | 6.7%(仅"a") |
| 语义准确率 | 0% |
技术工作全部成功,唯一失败的环节是:在没有映射表的情况下,从密文反推原文的语义。
这不是Kimi Flash的特定缺陷,而是这个加密方案针对"AI推断攻击"设计的固有防御。短消息+新映射表+语义歧义+语境误导,四个条件同时满足时,任何基于推断的破解方法在信息论层面都无法得出唯一正确答案。
想亲自测试这个加密器的,可以看文章开头的链接。